In conversation with Masaya Ishino, a key player behind ATLAS' successful Run 2
7 October 2019 | By
“I always do that, get into something and see how far I can go.” ― Richard P. Feynman.
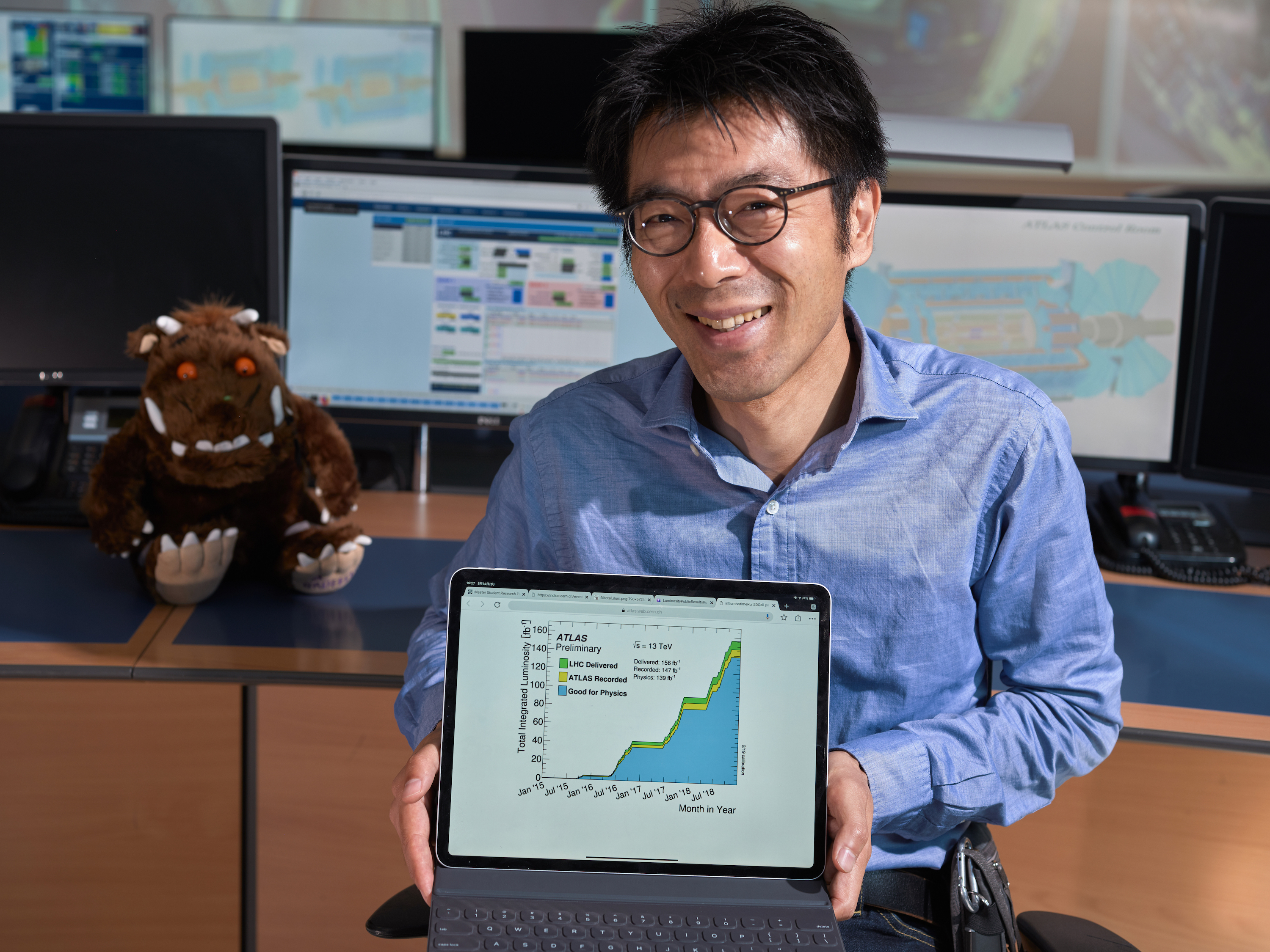
Like many physicists, Masaya Ishino was inspired to join the field after reading the works of Richard Feynman as a teenager. Surely, he thought, if I become a physicist, my life will be as fun as Mr. Feynman’s. Today, Masaya is a researcher and professor with the University of Tokyo. He joined the ATLAS Collaboration in 2001, and has been instrumental to the development, construction and operation of the muon spectrometer. Masaya was elected ATLAS Run Coordinator in 2017, playing a key role in the record-breaking Run 2 operation.
I began my career at the now-retired KEK Proton Synchrotron, working on a very small experiment – with only six students and one supervisor. I had the opportunity to experience every phase of the experiment, from design and construction to data taking and physics analysis. In such conditions, I could decide everything, in principle. We were only a few people, and all of us were true experts on the experiment. We knew each other very well, and everyone understood the experiment deeply.
While such a situation is quite different to those at ATLAS, there are still several similarities. For example, in small experiments, many things are often entrusted to just one person. I think we still see such a thing in ATLAS. There are several cases here where a very important subject can be the responsibility of a single person the experiment relies on.
As a university professor and supervisor, I find this means that my students can play a very important role in ATLAS, albeit with a narrow scope. Despite its size, there remains potential to gain recognition within the large ATLAS Collaboration, as my student Takuto Kunigo did last year when he won an ATLAS outstanding achievement award. He was able to find a good topic and do it well, making a substantial contribution to the collaboration. In this respect, it is similar to what I did in my small-size experiment.
Providing such opportunities to students can be simple when experts, over the course of their work, keep up a list of tasks that would benefit the experiment. Such lists of needed and simple-to-start tasks can allow supervisors to easily find useful ways for their students to contribute.
Operations were very different in the early days of ATLAS. Much had to be done manually and many parts of our systems relied solely on expert intervention.
After I completed my PhD, it seemed only natural to me to join one of the teams working on the ATLAS experiment. I joined the University of Tokyo team in 2001, developing and constructing Thin-Gap Chambers (TGC) for the muon spectrometer, and soon moved to CERN to work on their installation and commissioning.
During this period, our team very carefully designed procedures not only for the installation of these detectors, but also their regular testing. This meant that, on the first day of collisions, we only had to make a single small adjustment to the trigger timing in order to synchronize it with the LHC clock. It was thus one of the first ATLAS systems to accomplish this, I think in large part owing to these rigorous preparations. It was just after this start-up that I took on my first operations role, as part of the TGC team.
Operations were very different in the early days of ATLAS. Much had to be done manually and many parts of our systems relied solely on expert intervention. As we accumulated experience with our detector, we learned what could be considered a typical programme to be fed back into the system for automation. Indeed, I think that the main difference between Run 1 and Run 2 – at least, in terms of operations – is automation. During the entire Run 2 period, we were able to make continuous improvements to our data-taking efficiency through automation in all the ATLAS systems. While there can be some trade off, I believe it remains important to scrutinise any place that can be automated, as that will improve our data taking performance for Run 3 and beyond.

I moved back to Japan in 2011, beginning a new job at Kyoto University. While I spent significant time teaching undergraduate and graduate students, about a third of my time could still be dedicated to working on the muon spectrometer. During Run 1, we found a problem with the purity of the events selected by the TGC trigger. The data sample was polluted with background events likely because of slow protons coming from the end-cap toroid.
When faced with such an issue, immediate action has to be taken. Our team took the issue seriously and defined a programme to resolve it. Such joint action – whether they are developed over organised meetings or simple corridor conversations – is what leads to the most successful solutions. In this case, we input information into our trigger from detectors preceding the toroid to dramatically improve the purity of the sampled events.
My tenure as Run Coordinator was made more eventful by the appearance of the troublesome “Gruffalo” in the LHC beam.
In 2016, I accepted a professorship with the University of Tokyo and once again found myself based at CERN. The following year, I was elected deputy Run Coordinator by the collaboration. Despite my prior experience in operations, taking on the role opened my eyes to the many interconnected systems at play in our experiment: from our small forward detectors to the LHC itself, every part plays a crucial role.
My tenure as Run Coordinator was made more eventful by the appearance of the troublesome “Gruffalo” in the LHC beam. The issues began in the summer of 2017 when, at one specific part of the accelerator (denoted “16L2”), the proton beam would frequently become unstable and have to be ejected. If allowed to continue, the Gruffalo would have significantly limited our data-taking plans for Run 2.

What was the cause of this instability? Investigating the problem, the LHC team found that the Gruffalo only seemed to awaken when the number of proton bunches in the beam increased. Likely, these were causing an electron cloud to form in the beam pipe. After a few weeks of trial-and-error, the LHC team implemented a new bunch scheme, originally developed as a possibility for the High-Luminosity LHC (HL-LHC). To reduce the buildup of electron clouds, the LHC beam would be filled with a series of 8 proton bunches, followed by 4 empty slots. This proved a success and 2017 data-taking could continue without further surprises, albeit under harsh proton pile-up conditions
Throughout this period, ATLAS operators were constantly on-call. Whenever there was beam loss due to the Gruffalo, the LHC team would want to test out new parameters, such as the bunch intensity or the number of bunches. Not always, but maybe 80% of these changes would affect our operation, and new techniques would have to be developed on the fly.
All of our teams were extremely adaptable, in particular the trigger operations team. There were occasions where I’d have to call them at 3am, describing a new beam configuration that would be in effect in 2 hours and would require a whole new trigger menu. Everyone took their work very seriously, making quick and accurate changes to their systems. Looking back on it, I am still very impressed by their hard work and professionalism. Without all of these committed ATLAS teams, we would not have been able to take such good data that year.
In 2018, we hadn’t expected the Gruffalo to reappear... but it did. The LHC had returned to the normal 25 ns bunch spacing and, for the first part of 2018, data taking went smoothly. But when the Gruffalo reappeared in May, another solution was called for. Taking on board input from all the experiments, the LHC team decided that we could limit the number of protons in a bunch and run continuously. This worked and the Gruffalo went back to sleep, allowing us to have a very good production year in 2018.
New viewpoints are always important, whether they come from other experts or fresh eyes. Indeed, a naïve question, asked in the process of learning, can sometimes point out a problem otherwise overlooked.
While my two-year tenure as Run Coordinator was challenging, I gained a lot of valuable knowledge and experience. An unexpected source of both came from the daily LHC meetings, where accelerator and experiment experts would confer. Prior to joining these meetings, I had assumed it might be difficult to reach consensus between all the experiments. To my surprise, instead they were a good, constructive place for discussion.
Between the experiments, we were almost always able to achieve reasonable solutions through one-on-one conversations. In the rare cases where this wasn’t possible, our discussion would grow to include other experts. Everyone in the room had a broad overview – not just of their system or experiment, but of the machine as a whole. While we all brought different opinions and views to the table, our focus was always to achieve the best possible LHC programme.
Of course, a compromise where no one is satisfied is useless. Yet during my time at these meetings, the conclusions we reached were almost always ones that everyone could be happy with. I am quite proud of what we achieved and would like to express my thanks to the LHC programme coordinators who brought us all together. Without their competent guidance, it could have been difficult to create such a constructive atmosphere.
New viewpoints are always important, whether they come from other experts or fresh eyes. Operating the detector is an important and deeply satisfying task, which should be on the to-do list of all ATLAS members – even those without specific experience. Indeed, a naïve question, asked in the process of learning, can sometimes point out a problem otherwise overlooked. I hope I took such questions seriously during the 2 years I spent as Run Coordinator, and encourage others to do the same.
Since completing my responsibilities as Run Coordinator, I have returned my focus to my research and teaching duties at the University of Tokyo. One of our key tasks is preparing the TGCs to operate at the HL-LHC. As a supervisor, I always try to convey to my students the need to balance different aspects of research for their careers to succeed. If you can fill multiple roles, you will be able to adapt according to the high time. While there will be periods when you can only focus on data analysis, there will be others where hardware or operations experience will be the most needed. Students should prepare in advance to take on these roles.
ATLAS Portraits is a new series of interviews presenting collaborators whose contributions have helped shape the ATLAS experiment. Look forward to further ATLAS Portraits in the coming months.