Re-hashing reconstruction
11 September 2011 | By
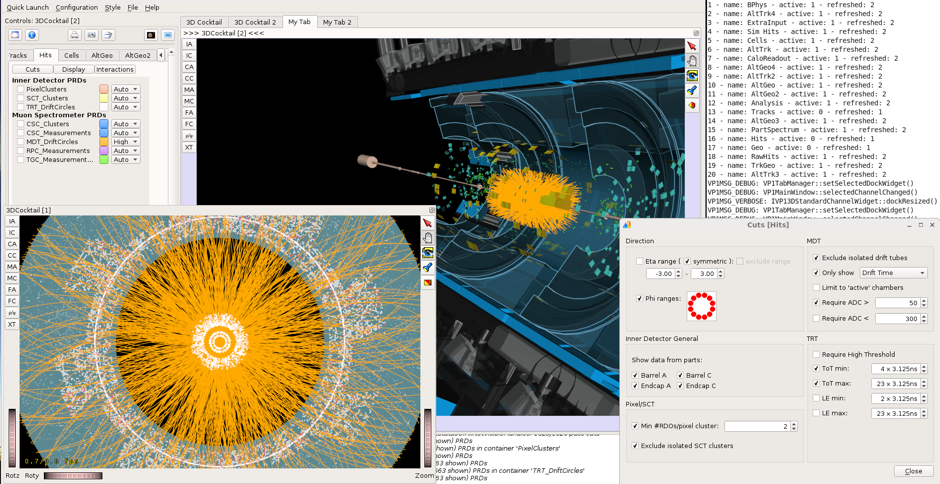
Now that the big summer conferences are under our belts, we’re busy reprocessing the data ATLAS has taken so far in 2011. The raw data we collect at ATLAS – basically millions of electrical signal values from the different bits of the detector (see Nick’s post for details of how the detector collects raw data) – has to be treated (‘reconstructed’) to turn it into meaningful physics data that can be analyzed for signs of new physics. The reconstruction transforms the raw electrical signals left by particles traversing the detector following a proton collision, piecing together the clues to build up a picture of their trajectories, energy and momentum. The bottom line is: without the reconstruction, we can’t produce any physics results.
Once or twice a year we re-run the reconstruction on the original raw data. Those ‘re’s can get confusing, but I’m about to add another, to simplify (!) things… We call the re-reconstruction ‘reprocessing’. You might wonder why we re-hash things like this (there’s another…). The answer is that the software we use to turn those electrical signals back into a picture of the real world is constantly improving. We’re learning and tweaking as we go along; six months after we first reconstruct a dataset, the algorithms and calibrations are more sophisticated than before, and can significantly improve the ‘physics potential’ of the data.
For example, this time around we’ll be able to measure the momentum of charged particles more accurately, because we’re using a more accurate alignment of the detector – we know in more detail which bits of the detector are shifted a millimeter to the left or right of perfect, and can correct for it.
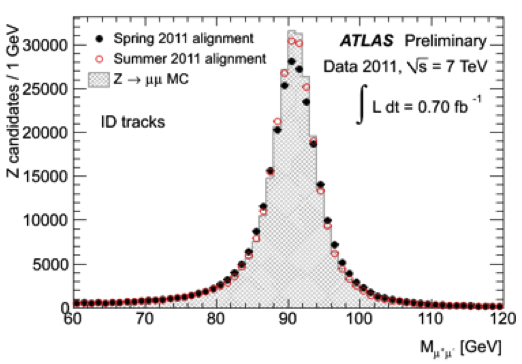
This rather technical looking plot shows the reconstructed mass of the Z0 boson decaying to 2 muons. You can see the improvement in detector alignment that we get using the reprocessed data. The red points are the reprocessed data and the black points the data with the old reconstruction. The grey shaded histogram shows what we would expect with perfect tracker alignment.
I’m one of the people organizing the reprocessing which is a quite a challenge. It involves people from all the different parts of the experiment, and from all over the world, so a lot of coordination – and a LOT of meetings – are needed! So far, apart from the odd minor hiccup, things have gone well – which is a big relief.
Many different parts of the experiment contribute to the reprocessing. New software and calibrations need to be carefully validated by each of the different physics and detector groups, and the computing experts are responsible for actually running the reprocessing at computing centers all over the world, using Grid technologies. Finally, the data-quality group carefully checks the reprocessed data to make sure it looks roughly as expected. Together, these groups add up to hundreds of people working hard to make sure the reprocessing is successful. In the latest ‘campaign’, we ran over about a billion events and produced more than a petabyte (that’s a million gigabytes!) of output data; it really is a huge undertaking.
Although reprocessing brings clear and important improvements to the physics data, it’s always difficult planning when the best time to carry it out is. It takes some time for the physicists doing analysis to study and understand the data that the updated software spits out, so each time we switch to a newer version, there’s a delay before physics results start appearing. This time, we chose to do it immediately after the Lepton-Photon conference, because the gap in the conference schedule gives us a bit of time to get used to the changes before presenting new results with the reprocessed data.
Reprocessing is a huge job, both computationally and organizationally, but every incremental improvement to the software and calibrations brings us closer to exciting new physics, like the Higgs boson or evidence of dark matter, and that makes it all worthwhile!
About the author(s)

Jamie Boyd
Jamie Boyd is a CERN Staff Scientist based in Geneva. He is ATLAS’s Deputy Data Preparation Coordinator, ensuring that billions of events worth of data are processed quickly and correctly so that hundreds of physicists can get to work analyzing them, and is searching for signs of the elusive dark matter.