Learning by machines, for machines: Artificial Intelligence in the world's largest particle detector
5 June 2024 | By
In today’s age, you can't do much without interfacing with artificial intelligence and machine learning (AI/ML). This technology lets you unlock your phone via face recognition, helps curate your social media feed and powers internet search. In the future, it promises to automate tasks as mundane as driving a car and as cerebral as scientific outreach. Its clear transformative capability has captured our collective attention, sparking dialogue across scientific communities, governments and the general public, alike. But long before ChatGPT or DALL-E, the basic statistical principles that underpin the world's most sophisticated ML tools were hard at work in the field of high-energy collider physics. Today, they are enabling unprecedented progress in understanding the nature of our fundamental universe.
High-energy physics (HEP) can trace its relationship with ML back many decades, with the earliest neural networks coming into play in the 1990s. ML algorithms improved Higgs-boson searches at CERN’s LEP collider, powered CP-violation measurements at the B factories at KEK and SLAC, and enabled the observation of single top-quark production at Fermilab's Tevatron collider. They were also key for the discovery and study of the Higgs boson as well as the observation of the ultra rare two-muon decay of the Bs meson at the LHC.
But it wasn't until the 2010s that modern computational power and methodological innovation enabled deep learning, and let AI-based research methods like ML really shine. In many ways, the relationship between particle physics and ML is a natural and symbiotic one. High energy particle collisions offer a means to study fundamental interactions under conditions similar to the early universe, allowing a window into potential particles or processes that are “frozen out” in the current universe. In this way, finding optimal and intelligent ways to sift through the trove of data from experiments at CERN’s Large Hadron Collider (LHC) is crucial, as it enables researchers to precisely characterise the Standard Model (SM) and understand mysteries like dark matter and matter-antimatter asymmetry that motivate new physics beyond the Standard Model (BSM).
Collider-based experiments led to some of the original “big data” problems. Experiments like ATLAS at the LHC operate with staggering data rates, producing over 60 terabytes per second, yet only some of these proton collision events may contain processes of interest. What's more, these experiments offer a dataset that is unique in its complexity and statistical power, in which new ML architectures or problems such as systematic biases or hardware optimization can be studied.
High-energy physics can trace its relationship with machine learning back many decades, with the earliest neural networks coming into play in the 1990s.
The task of operating the ATLAS experiment and extracting results from its vast datasets is a computational labyrinth. From its inception in the 1990s, the ATLAS experiment was designed to process every proton collision digitally. Within seconds of a collision the data from millions of sensors have been filtered through a web of custom electronics and analysed on a computing farm with tens of thousands of CPUs. Collisions of interest are recorded and reanalysed countless times by physicists looking to better understand the nature of the universe. In all cases the goal of this analysis is to discover precisely what happened at the interaction point, where two protons travelling at 99.999999% the speed of light collide in the accelerator, producing a plethora of new particles.
Unfortunately, the physics at the interaction point can be elusive. Many of the most interesting SM or BSM particles produced in the proton collision will decay in less than one trillionth of one trillionth of a second! Physicists can only pick up on hints of SM or BSM physics by looking for the decay products of the most interesting particles, which may themselves decay before reaching any sensors in ATLAS. From a single collision the ATLAS experiment may record thousands of individual particles, and to make matters worse, it typically has to deal with dozens of simultaneous collisions. To understand what happened at the interaction point, physicists must carefully reconstruct, identify and measure each of these particles. These are then used to reconstruct the entire collision event, which are scoured for processes of interest that may lead to a better understanding of known particles, or shed light on the existence of never-before-observed ones.
ML methods are designed to harness large amounts of data in order to infer new information, making them naturally suited to various data processing tasks in ATLAS, from the moment a particle hits the detector all the way to the final published results. The examples that follow give a representative idea of how extensively this technology has pervaded the experiment, but merely scratch the surface of the full picture and potential of ML in HEP.
Machine learning at work in ATLAS
During regular operation of the ATLAS experiment, the first challenge is what to do with the data that is created. With multiple subsystems, an LHC collision frequency of 40 million per second and millions of individual channels of data to read out, the ATLAS experiment produces a data rate far greater than can possibly be written to disk. A complex trigger system implements algorithms that rapidly evaluate incoming data events to determine if they are interesting enough to keep, rejecting the overwhelming majority of events produced.

This task requires sophisticated inference that can be done very quickly, introducing the use of “fast ML” to accelerate ML algorithms traditionally run in software for use in hardware such as field-programmable gate arrays (FPGAs). This process allows for greater intelligence closer to the source of the data, leading to more accurate reconstruction and better trigger decisions. For example, the energy and timing of signals in the ATLAS electromagnetic calorimeter subsystem can now be estimated by convolutional and recurrent ML architectures in real time of LHC operation, outperforming existing signal filters (Figure 1). This capability of ML to perform fast and accurate regression of key physical quantities can also be used for more accurate calibrations of detector signals.
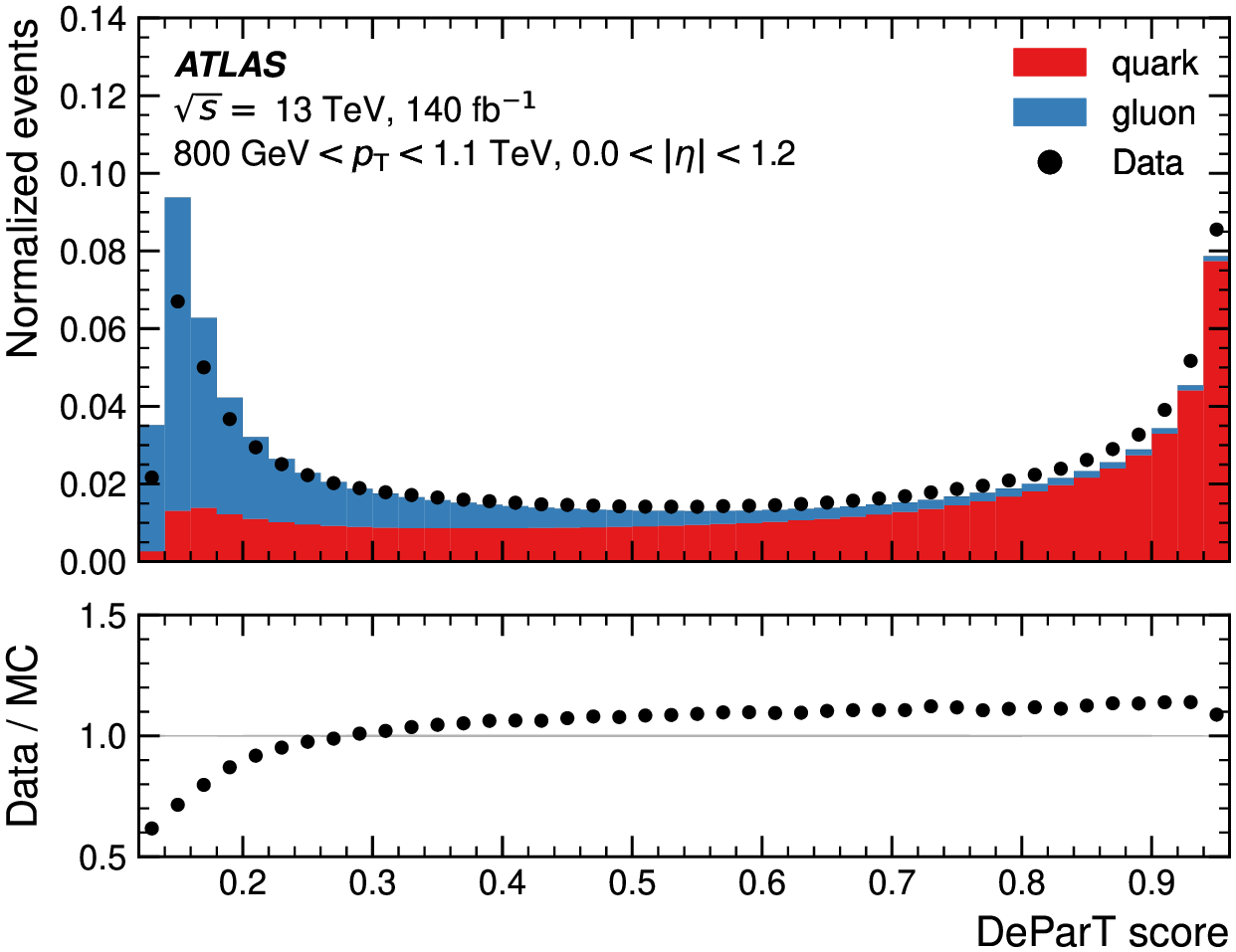
AI/ML also comes into play in the reconstruction algorithms that turn detector signals into physics objects. Well before ATLAS recorded its first data, physicists had developed hundreds of algorithms to reconstruct specific particle types based on the signatures they leave in the different ATLAS sub-detectors. Some particles, like b-hadrons, will decay before reaching any of the ATLAS sub-detectors, and are discerned by triangulating the trajectories of the decay products back to a displaced vertex that is separated from the proton collision point by just a few millimetres. ML has proved essential in identifying this distinctive signature. The latest tools to identify b-hadrons in the detector make use of cutting-edge architectures, such as transformers with attention mechanisms that carefully study simulated b-hadron decays and learn to reject vertices from regular light quark processes at the best rate achieved in ATLAS to date. Transformers have also been used to learn the complex signature of a particle decaying to two b-hadrons when the decay is collimated and the b-hadron tracks are overlapping.
Machine-learning methods are designed to harness large amounts of data in order to infer new information, making them naturally suited to various data processing tasks in ATLAS.
Once the data have been recorded and the events are reconstructed, it's time to study the underlying physics mechanism that produced the event. ATLAS physics analyses are predicated on effective solutions to classic signal-to-noise problems. Many processes of interest are incredibly rare and can be challenging to distinguish among the billions of ordinary proton collisions. Here is where ML can shine: its broad ability to exploit subtle features within a complex and high-statistics dataset make it a primary workhorse for isolating interesting signal processes.

No particle has held more interest in the past decade than the Higgs boson, discovered in 2012 by the ATLAS and CMS experiments and met with great fanfare and excitement. Understanding and characterising the Higgs boson and the underlying mechanism of mass generation remains an essential goal of high-energy physics today, and ML is in use throughout Higgs-boson analyses. The 2018 observation of the Higgs boson in its most common, but trickiest, decay channel, H→bb, made use of a classic boosted decision tree (BDT) architecture to classify the Higgs-boson signal from the overwhelming background of multijet processes to make observation possible (Figure 2).
ML has also enabled unprecedented study of the top quark, the heaviest known particle and one with a particularly interesting connection to the Higgs boson. In 2023, researchers adapted a graph neural network to model collisions in a geometrical way using the particles produced during the collision and their relationship to one another in the detector space. Training this model to separate the rare four-top-quark-production process from SM backgrounds allowed ATLAS to make its first statistically confident observation of such events, along with a measurement of its production rate and constraints on key possible extensions of the SM.
While these examples of ML to isolate a specific signal demonstrate the depth of its effectiveness, another implementation of ML can reveal its breadth. A growing interest in the LHC community in anomaly detection has led to the proliferation of ML methods that can isolate unusual phenomena from a well-known background model. Such an approach lowers the need to rely on a specific signal model, making these search techniques very broad and sensitive to new physics that may have been missed by previous analysis approaches. In recent years, ATLAS published its first use cases of anomaly detection, implemented via ML algorithms without complete labelling information of training inputs, all in the context of searches for new heavy particles decaying to two-object final states (Figure 3). These analyses leveraged the power of data-driven ML training through a mix of conventional and novel architectures to perform model-independent searches for new particles with a variety of mass and decay hypotheses, providing an invaluable new approach for extracting the most from the ATLAS dataset.

Subtleties and challenges
Despite these successes, there's no such thing as a flawless solution. While ML can offer incredible benefits to ATLAS throughout all stages of the analysis chain, its usage has to be closely coupled with continuous monitoring. Models can inherit unintended biases in the course of training, leading it to make spurious or, even worse, incorrect inferences. The risk of such biases is so significant that it has spawned a broader subfield of AI alignment and safety, and must be carefully considered when applying ML tools to produce physics results.
Luckily there are many ways ATLAS physicists can tackle this challenge. One potential source of such bias emerges from the use of simulated collision events to develop ML tools. While physicists have invested decades into generating accurate and fast simulations, there are still some known ways in which their predictive capabilities can break down. Furthermore, the development of a tool using a particular selection of data with limited statistical power can often require the intentional decorrelation of the model's learned conclusions from certain sensitive properties that should not be considered. To address these issues, physicists make use of dedicated de-biasing or decorrelation techniques from the HEP-ML research community, such as moment decomposition or distance correlation. The limitations of statistical power in simulation samples used for training can also be mitigated through the use of fast simulation methods, which use ML to circumvent the costly full Monte Carlo simulation chain by making fast estimations of key collision and detector properties.
While machine learning can offer incredible benefits to ATLAS throughout all stages of the analysis chain, its usage has to be closely coupled with continuous monitoring.
On top of it all, developing, training and running these advanced algorithms takes a staggering amount of power. To run and adequately cool the mainframes and supercomputers of the CERN Data Centre takes about 37 gigawatt-hours per year, about 3% of CERN's total annual electrical consumption when the LHC operates. While this computing covers all CERN operations, including many applications beyond AI/ML development, producing this quantity of electricity has a significant carbon footprint. The growing role of AI/ML, combined with the uptake of larger and larger models, means that associated power consumption will likely increase as well; for context, Open AI’s ChatGPT uses half a gigawatt-hour daily! Greener approaches are being investigated to continue these operations at CERN in an increasingly climate-focused society. Through dedicated sustainability initiatives, CERN is working with experts across areas of research to find environmentally friendly data management solutions and greener ways to run collider experiments.
A new AI era of scientific research
With this striking history of success, and expectations for computational power to continue its tremendous rise, the future of ML in high-energy physics is bright. ATLAS researchers are collaborative by nature, and much of the work described here wouldn't be possible without close ties to the computer science and AI/ML research communities. Maintaining and expanding these relationships means that physics experimentation will continue to benefit from the latest and greatest in ML algorithms and software capabilities. A recent push across CERN to provide more "open data" recorded by the experiments will further engage researchers outside of HEP who can benefit from the uniquely complex and high-statistics LHC datasets to design and optimise their tools.
Beyond the horizons of ATLAS, AI/ML techniques are similarly impacting the broader landscape in physics. Within theoretical physics, ML offers the promise of dramatically reducing computation cost/time of challenging calculations and simulations, among other things. Further, ML is being studied to perform comprehensive optimizations of future detector designs, which comes at an exciting time for the strategic planning of next-generation colliders.
The long-term future of AI will have an impact on our world that is exciting, transformative and yet unimaginable – and things are no different for particle physics. Through continued collaboration and thoughtful planning for the potential ethical and environmental consequences, researchers can properly harness AI/ML to usher in a new era of precision understanding (and potentially groundbreaking discoveries) in particle physics.
The author would like to thank Katarina Anthony, Dan Guest, Andreas Hoecker, Walter Hopkins, Michael Kagan, Zach Marshall, Benjamin Nachman, and Manuella Vincter for their input and feedback.
About the Author
Julia Gonski is a Panofsky Fellow (associate staff scientist) working on the energy frontier at SLAC National Accelerator Laboratory. Her research focuses on novel approaches to searching for beyond the Standard Model physics with the ATLAS experiment, particularly incorporating machine learning (ML) and anomaly detection. She also works on fast ML for electronics in advanced trigger and readout systems, and planning for next-generation global collider facilities.
Further Reading
- ATLAS searches for new phenomena using unsupervised machine learning for anomaly detection, ATLAS Physics Briefing, August 2023
- Higgs boson observed decaying to b quarks – at last!, ATLAS Physics Briefing, July 2018
- All ATLAS updates on machine learning
- All CERN updates on sustainability
Scientific articles
- Artificial Neural Networks on FPGAs for Real-Time Energy Reconstruction of the ATLAS LAr Calorimeters (ATL-LARG-PROC-2021-001 (2021))
- The application of neural networks for the calibration of topological cell clusters in the ATLAS calorimeters (ATL-PHYS-PUB-2023-019 (2023))
- Flavour tagging with graph neural networks with the ATLAS detector (ATL-PHYS-PROC-2023-017 (2023))
- Transformer Neural Networks for Identifying Boosted Higgs Bosons decaying into bb and cc in ATLAS (ATL-PHYS-PUB-2023-021 (2023))
- Observation of four-top-quark production in the multilepton final state with the ATLAS detector (Eur. Phys. J. C 83 (2023))
- Dijet resonance search with weak supervision using 13 TeV pp collisions in the ATLAS detector (Phys. Rev. Lett. 125, 131801 (2020))
- Anomaly detection search for new resonances decaying into a Higgs boson and a generic new particle X in hadronic final states using 13 TeV pp collisions with the ATLAS detector (Phys. Rev. D 108, 052009 (2023))
- Search for new phenomena in two-body invariant mass distributions using unsupervised machine learning for anomaly detection at 13 TeV with the ATLAS detector (arXiv:2307.01612)
- Deep Generative Models for Fast Photon Shower Simulation in ATLAS (Computing and Software for Big Science Vol 8 #7 (2024))